Muhammad Shakeel, Ph.D.

Scientist
Honda Research Institute Japan Co., Ltd.
As a Scientist at Honda Research Institute Japan Co., Ltd., my research is centered on developing the next generation of automatic speech recognition (ASR) technologies. While my published work has focused on foundational models and contextual ASR, my current passion and research efforts are increasingly directed toward the complex challenges of multi-speaker ASR and speaker diarization, aiming to create systems that can robustly process real-world conversational audio.
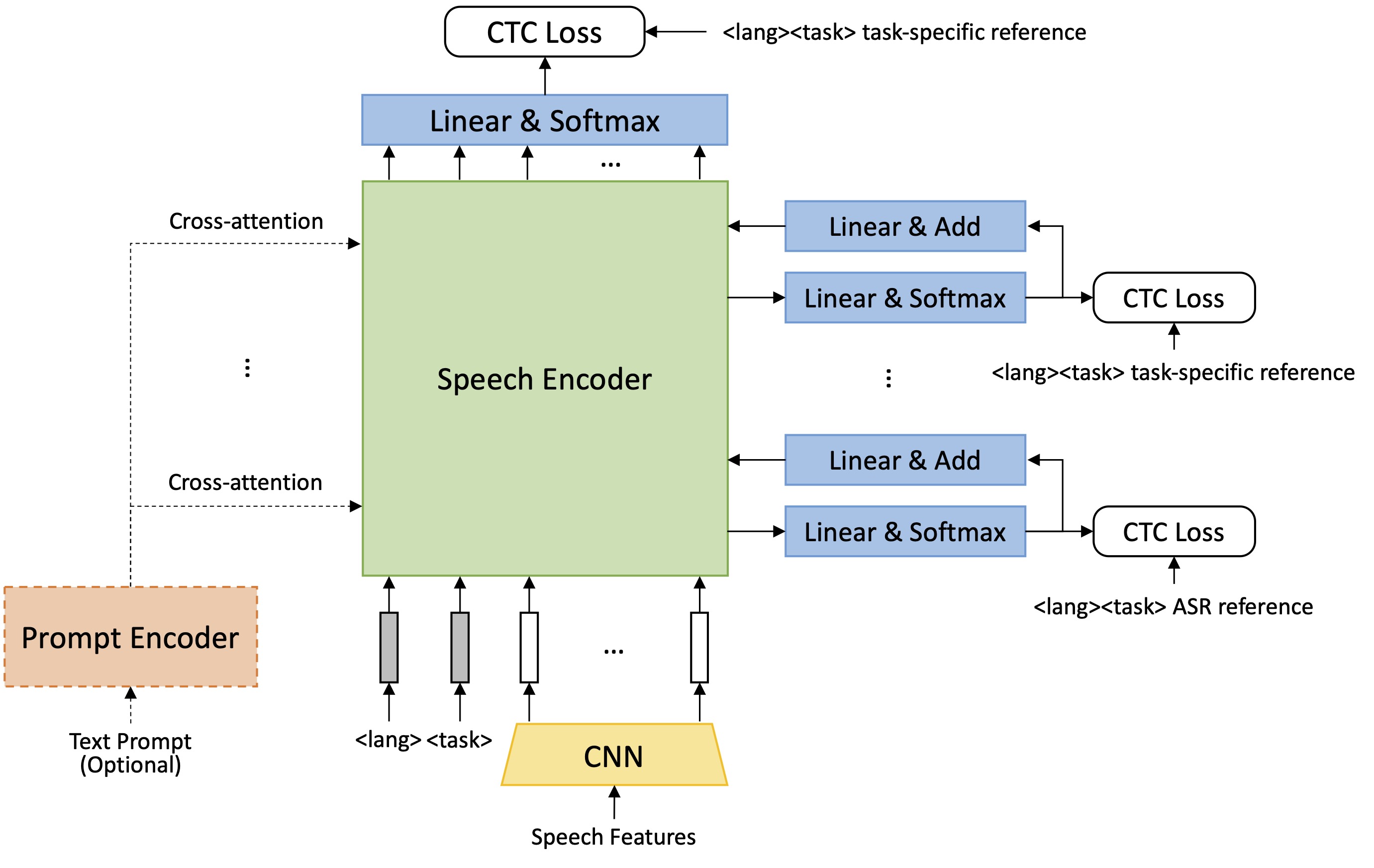
This has involved contributing to large-scale, open speech foundation models, most notably through a collaboration with Language Technologies Institute at Carnegie Mellon University on the Open Whisper-style Speech Model (OWSM) project. Within this initiative to create transparent alternatives to proprietary models, the focus has been on architectural innovation. This included enhancing the model with E-Branchformer for better performance and developing non-autoregressive systems like OWSM-CTC to achieve significant gains in speed and robustness against model hallucination.
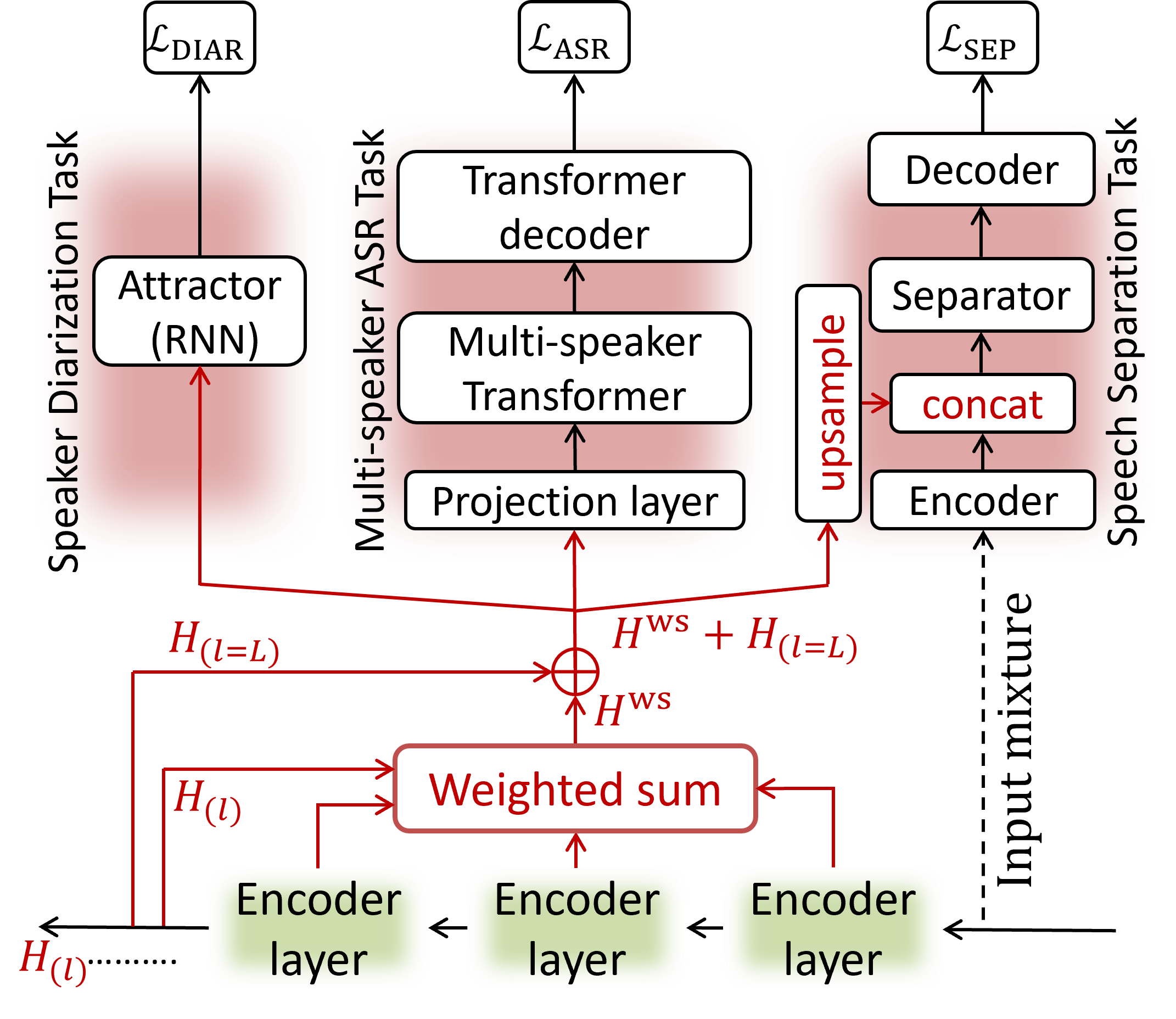
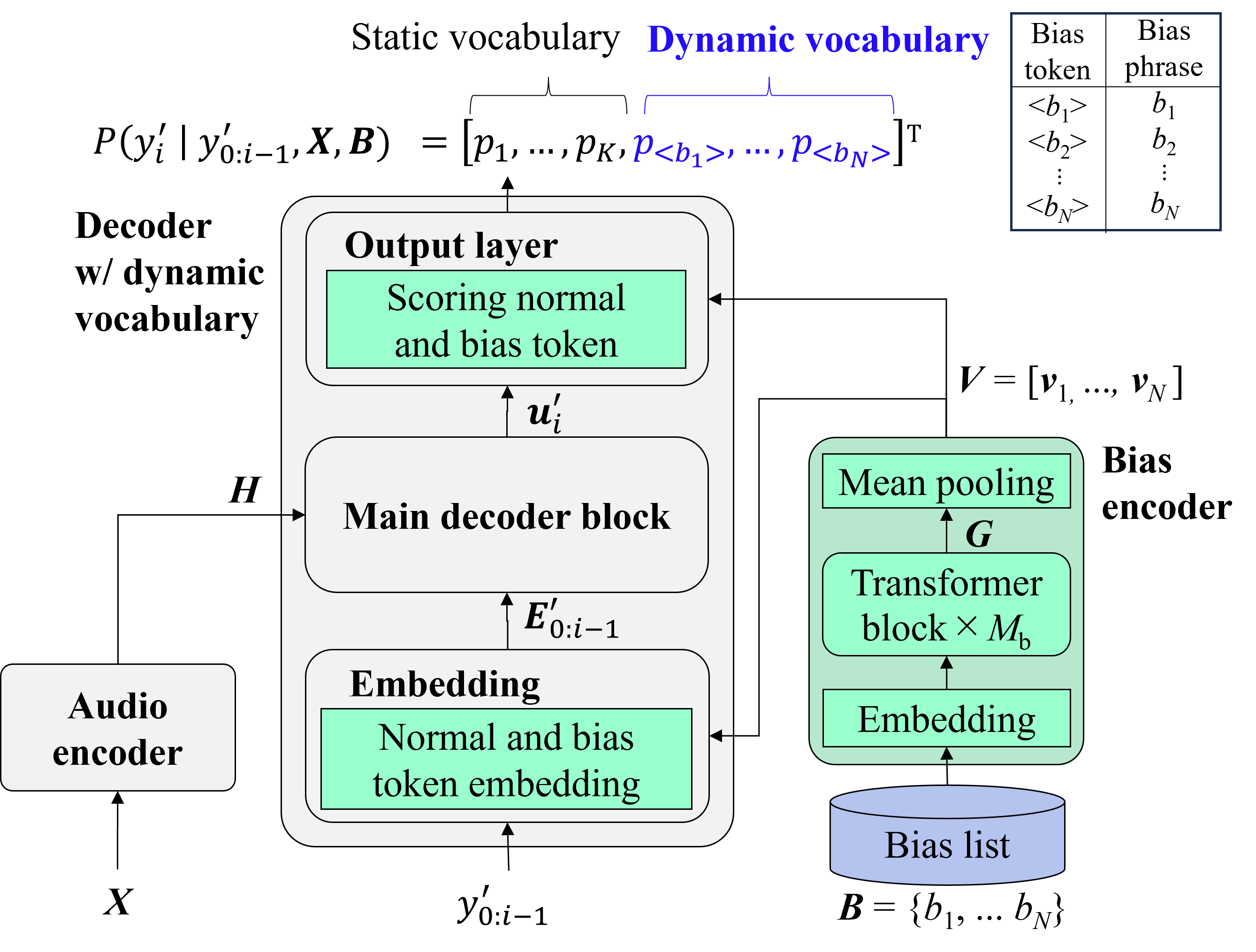
This work on foundational models naturally highlights the critical need for both practical applicability and computational efficiency. To address this, my research has explored several interconnected areas. To improve real-world utility, investigations into contextual ASR have yielded novel methods for recognizing rare and user-specific terminology through techniques like dynamic vocabularies, intermediate biasing losses, and a bias phrase boosted (BPB) beam search. Simultaneously, to enhance architectural robustness and flexibility, contributions were made to unified systems like the 4D ASR model, which integrates multiple decoder paradigms (CTC, Attention, RNN-T, and Mask-CTC) into a single, jointly trained framework. This theme of unification also extends to addressing deployment constraints, as seen in work on jointly optimizing streaming and non-streaming ASR. Recognizing that the utility of large models is ultimately gated by their deployability, another facet of this research has been model efficiency, demonstrated through contributions to compression techniques like joint distillation and pruning in the DPHuBERT work.
The pursuit of scientific advancement is a cumulative effort, built upon the foundational work of those who came before. As Sir Isaac Newton famously wrote, “If I have seen further, it is by standing on the shoulders of Giants.” This idea has been a guiding principle throughout my research career, which has been profoundly shaped by the mentorship and collaboration of distinguished researchers. In my current role at Honda Research Institute Japan, I am honored to be collaborating with Prof. Shinji Watanabe, whose pioneering work continues to shape the field of end-to-end speech recognition. This opportunity builds upon the excellent guidance I received during my academic journey: my doctoral studies were supervised by Prof. Kazuhiro Nakadai at the Tokyo Institute of Technology (now Institute of Science Tokyo); my master’s thesis was a collaborative effort guided by Prof. Satoshi Tadokoro of Tohoku University and Prof. Daniele Nardi of Sapienza University of Rome; and my foundational research experience, contributing to the ALICE experiment at CERN, was conducted under the supervision of Prof. Arshad Saleem Bhatti.
Honors and Awards
| Aug 22, 2025 | ISCA Best Student Paper Award (2025) |
|---|---|
| Dec 04, 2024 | IEEE SLT Best Paper Award (2024) |
| Mar 22, 2019 | Fully funded Ph.D. Research Fellowship (MEXT) |
| Sep 01, 2013 | Tohoku University Exchange Programme |
| Jun 10, 2011 | Erasmus Mundus Scholarship |
News
| Aug 22, 2025 | |
|---|---|
| Aug 06, 2025 | |
| May 19, 2025 | |
| Dec 04, 2024 | |
| Aug 30, 2024 | |
| Jun 04, 2024 | |
| May 16, 2024 | |
| Feb 03, 2024 | |
| Dec 13, 2023 | |
| Sep 22, 2023 | |
| May 17, 2023 | |
| Nov 01, 2022 | |
| Sep 20, 2022 | |
Selected publications
- CONFERENCE INTERSPEECH Contextualized ASR
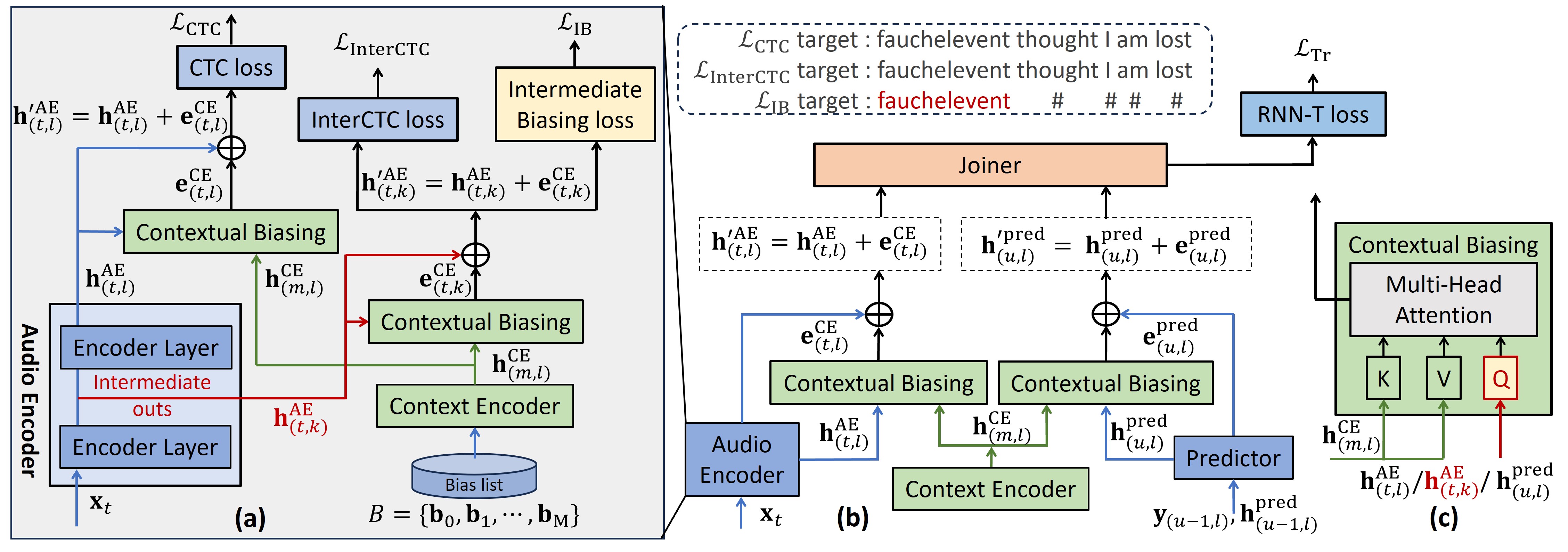 Contextualized End-to-end Automatic Speech Recognition with Intermediate Biasing LossIn Proceedings of the Annual Conference of the International Speech Communication Association (INTERSPEECH), Sep 2024
Contextualized End-to-end Automatic Speech Recognition with Intermediate Biasing LossIn Proceedings of the Annual Conference of the International Speech Communication Association (INTERSPEECH), Sep 2024 - WORKSHOP ICASSPW Unified Model
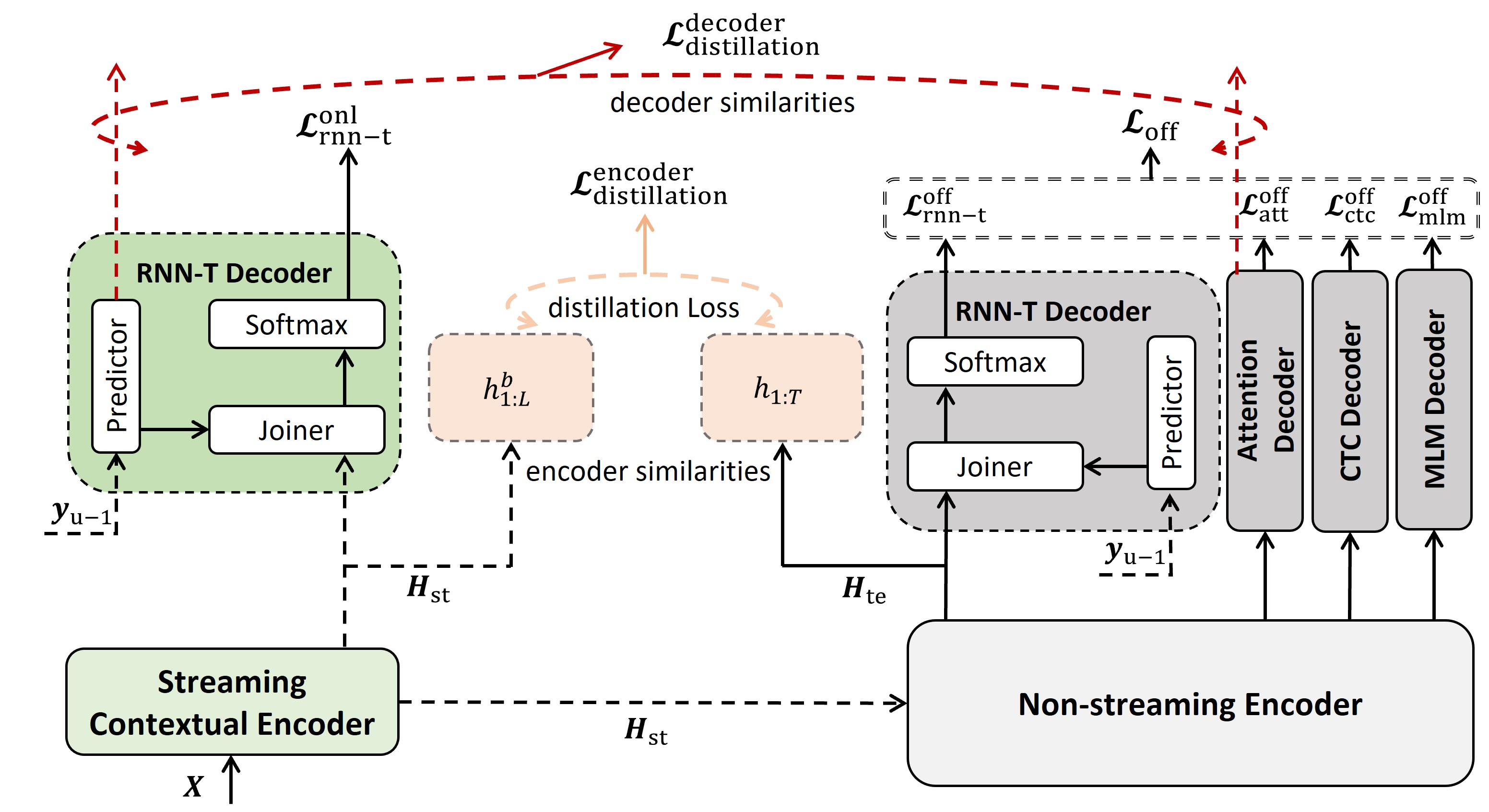 Joint Optimization of Streaming and Non-Streaming Automatic Speech Recognition with Multi-Decoder and Knowledge DistillationIn IEEE International Conference on Acoustics, Speech, and Signal Processing Workshops (ICASSPW), Apr 2024
Joint Optimization of Streaming and Non-Streaming Automatic Speech Recognition with Multi-Decoder and Knowledge DistillationIn IEEE International Conference on Acoustics, Speech, and Signal Processing Workshops (ICASSPW), Apr 2024