Muhammad Shakeel, Ph.D.

Scientist
Honda Research Institute Japan Co., Ltd.
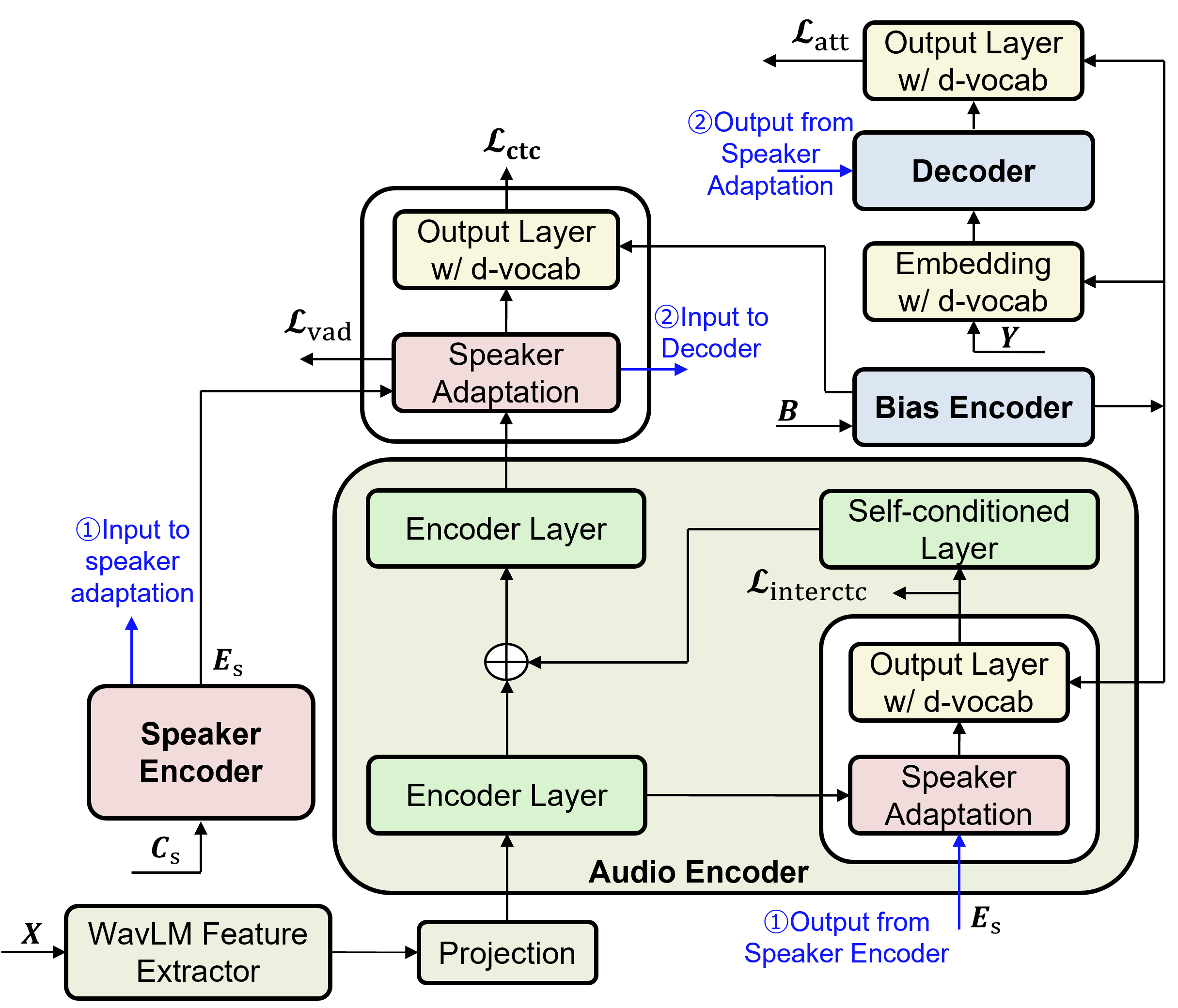
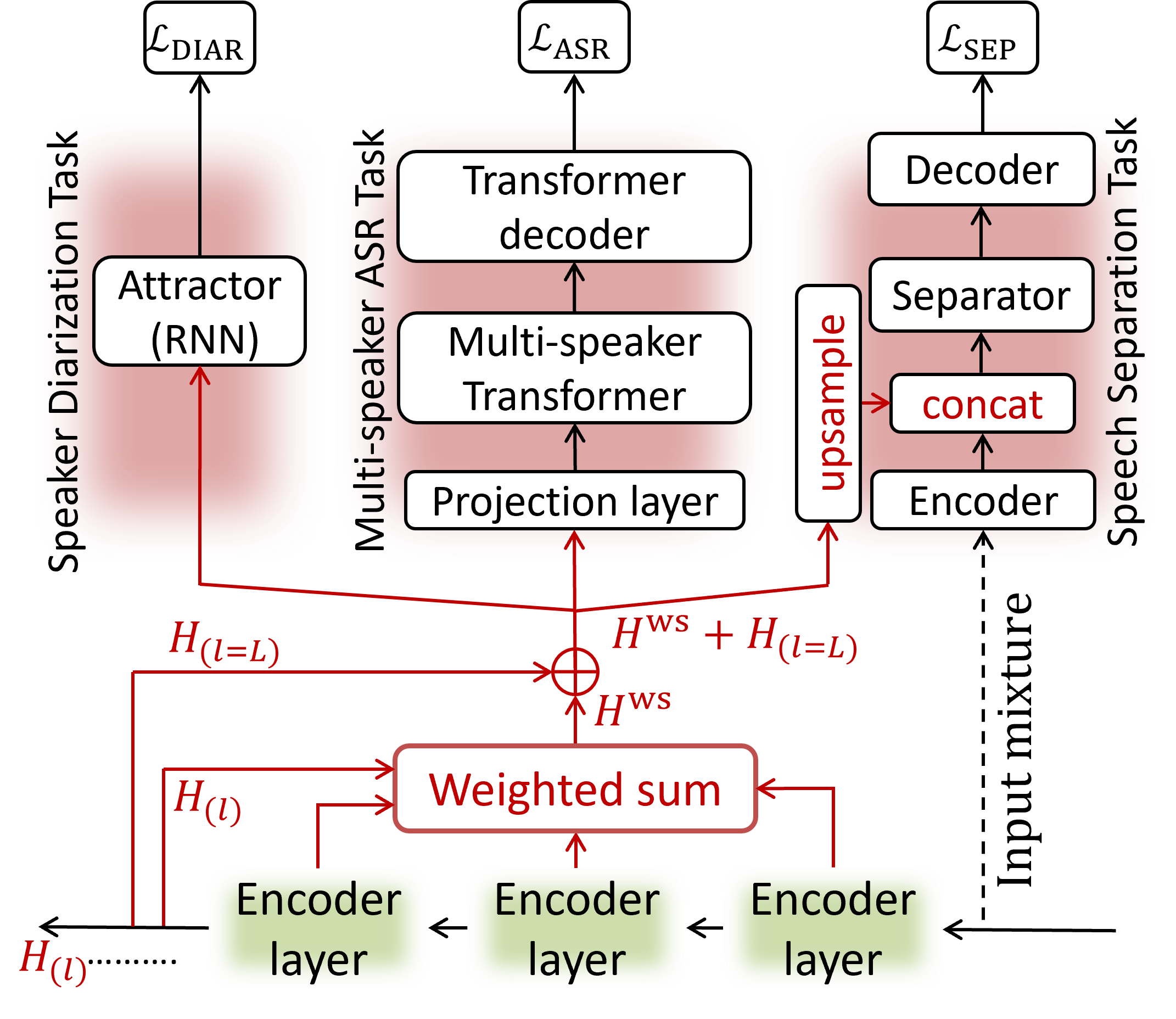
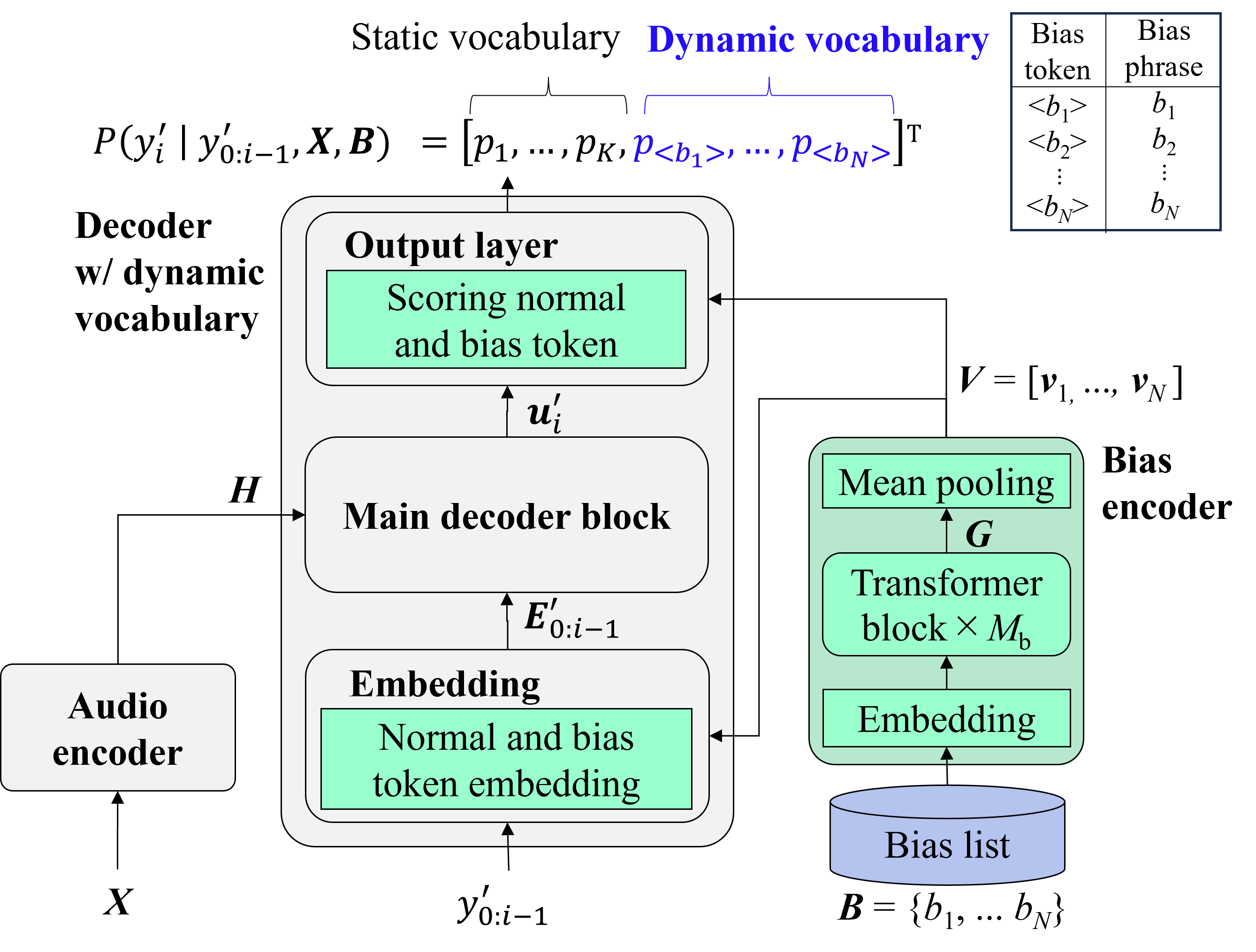
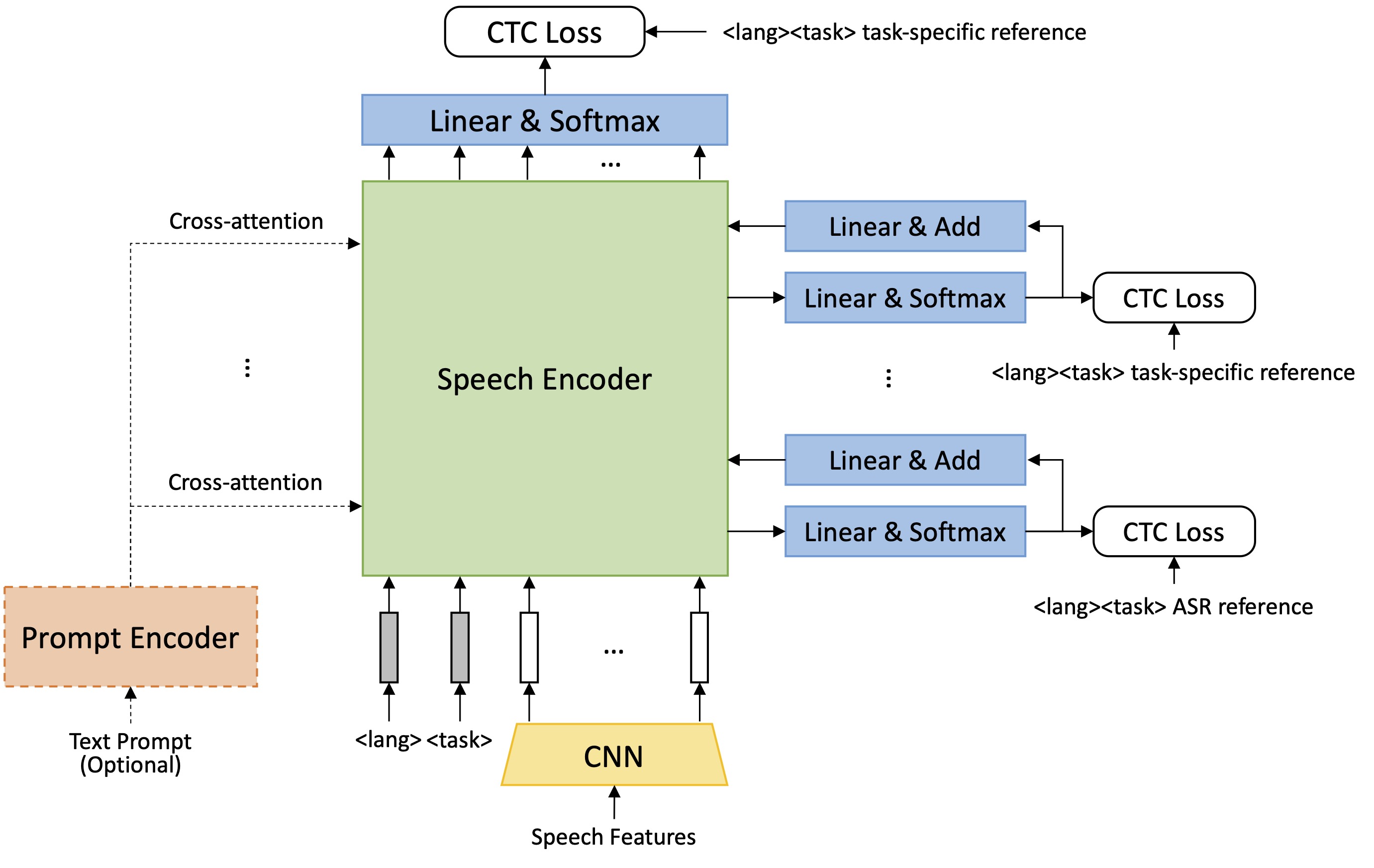
I am a Scientist at Honda Research Institute Japan Co., Ltd., where I advance next-generation speech capabilities. My research focuses on multilingual speech processing, specifically multi-speaker ASR and speaker diarization. I specialize in contextual biasing for personalization and advancing speech model architectures.
Most recently, I collaborated with Carnegie Mellon University on the Open Whisper-style Speech Model (OWSM) project, advised by Prof. Shinji Watanabe.
I hold a PhD from the Tokyo Institute of Technology (now Institute of Science Tokyo), where I was advised by Prof. Kazuhiro Nakadai. My academic foundation includes a collaboration with the ALICE experiment at CERN while serving as a Lecturer at COMSATS University Islamabad (advised by Prof. Arshad Saleem Bhatti), and a joint Master’s thesis between Tohoku University and Sapienza University of Rome (advised by Prof. Satoshi Tadokoro and Prof. Daniele Nardi).
Honors and Awards
| Aug 22, 2025 | ISCA Best Student Paper Award (2025) |
|---|---|
| Dec 04, 2024 | IEEE SLT Best Paper Award (2024) |
| Mar 22, 2019 | Fully funded Ph.D. Research Fellowship (MEXT) |
| Sep 01, 2013 | Tohoku University Exchange Programme |
| Jun 10, 2011 | Erasmus Mundus Scholarship |
News
| Jan 17, 2026 | |
|---|---|
| Aug 22, 2025 | |
| Aug 06, 2025 | |
| May 19, 2025 | |
| Dec 04, 2024 | |
| Aug 30, 2024 | |
| Jun 04, 2024 | |
| May 16, 2024 | |
| Feb 03, 2024 | |
| Dec 13, 2023 | |
| Sep 22, 2023 | |
| May 17, 2023 | |
| Nov 01, 2022 | |
| Sep 20, 2022 | |
Selected publications
- CONFERENCE INTERSPEECH Contextualized ASR
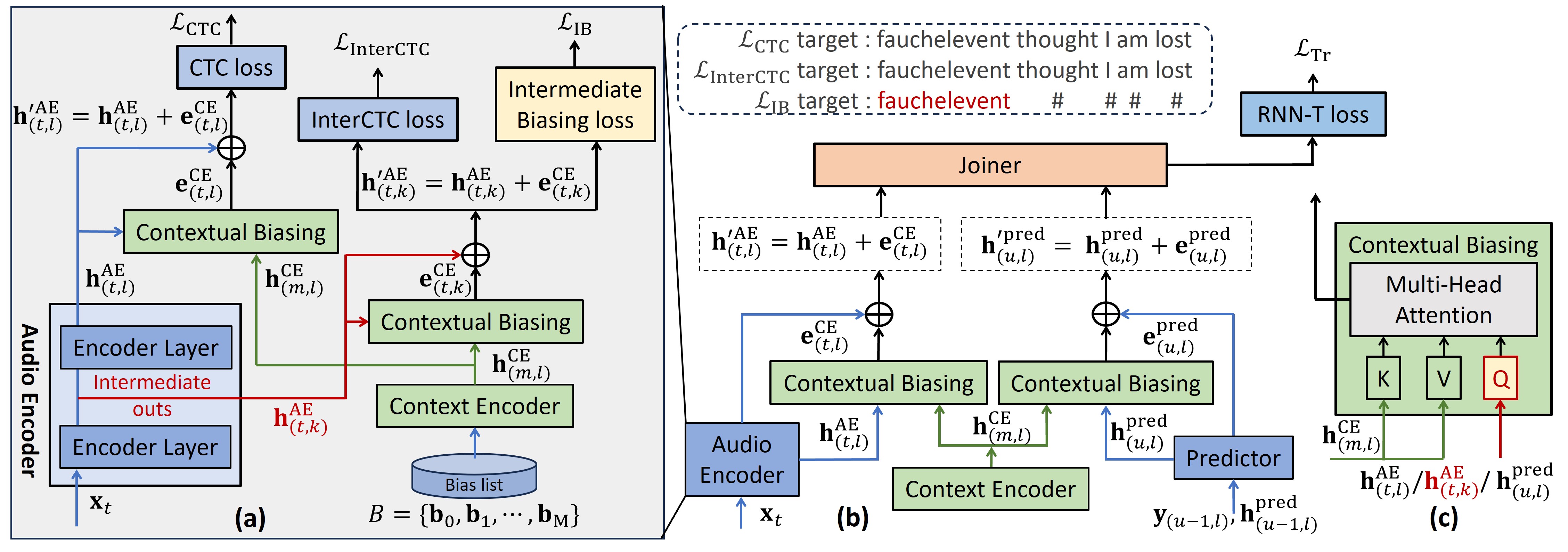 Contextualized End-to-end Automatic Speech Recognition with Intermediate Biasing LossIn Proceedings of the Annual Conference of the International Speech Communication Association (INTERSPEECH), Sep 2024
Contextualized End-to-end Automatic Speech Recognition with Intermediate Biasing LossIn Proceedings of the Annual Conference of the International Speech Communication Association (INTERSPEECH), Sep 2024 - WORKSHOP ICASSPW Unified Model
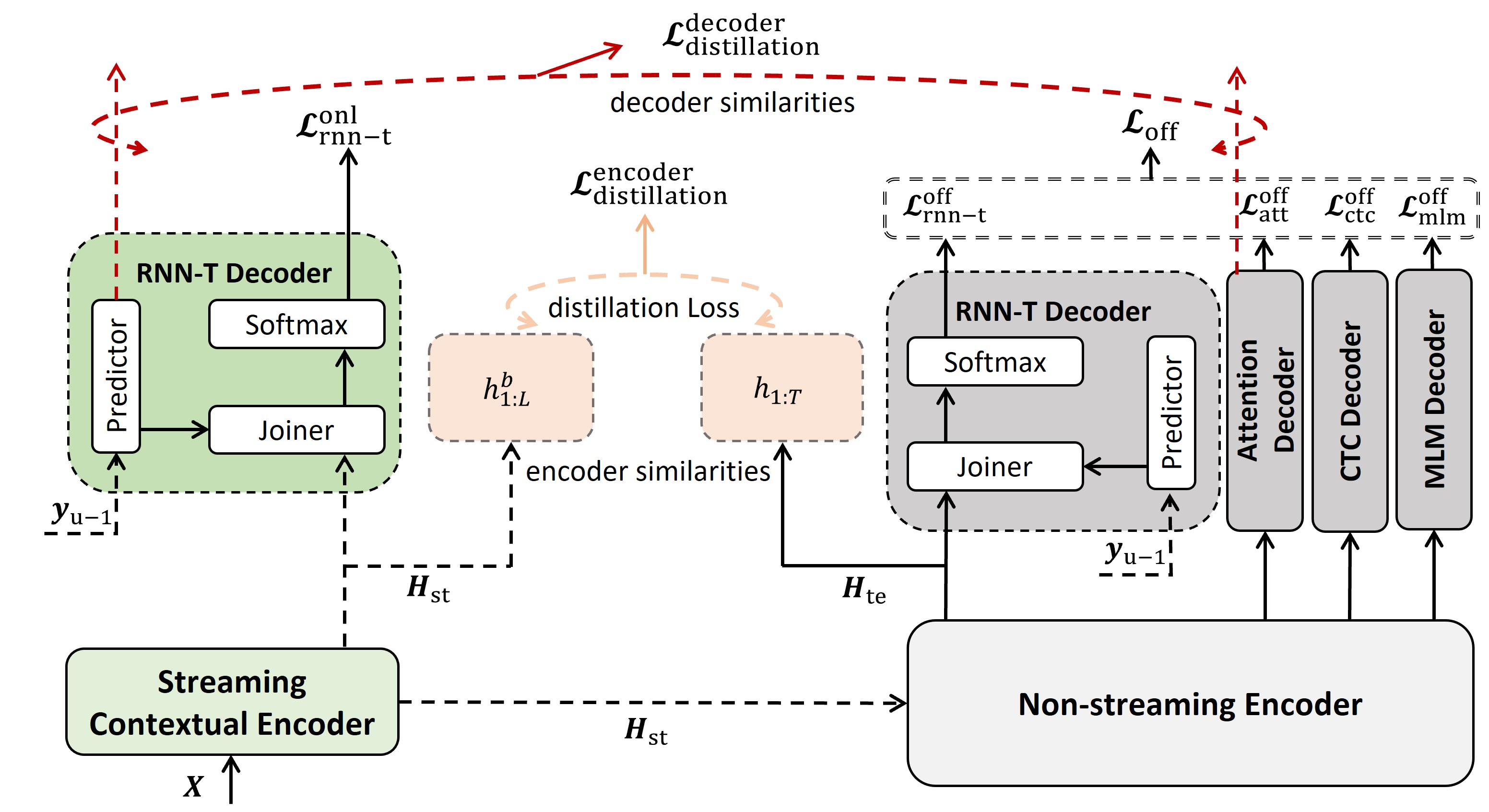 Joint Optimization of Streaming and Non-Streaming Automatic Speech Recognition with Multi-Decoder and Knowledge DistillationIn IEEE International Conference on Acoustics, Speech, and Signal Processing Workshops (ICASSPW), Apr 2024
Joint Optimization of Streaming and Non-Streaming Automatic Speech Recognition with Multi-Decoder and Knowledge DistillationIn IEEE International Conference on Acoustics, Speech, and Signal Processing Workshops (ICASSPW), Apr 2024